Also I said that I’m out of the RapidMiner – Rosette API challenge, here is what I was trying to achieve. Failing is always part of learning and I hope that the few things I learned may help you anyway.
I had a few ideas on the use of sentiment analysis offered by Rosette and already mined the subreddit /r/netrunner but later dropped the idea. Between Christmas and New Year I watched David Kriesels talk about data mining big media distributor SpiegelOnline.de and was psyched if I can do something similar with it.
David Kriesel is collecting articles from German news site SpiegelOnline.de for a few years now and did some data science on their meta data. So I mined as many articles whose URL contained the term “fussball” (football or for pesky Americans “soccer”). After a few evenings of tinkering with RapidMiners web crawling operators I had about 9000 articles collected and felt I was set.
I cleaned up the xhtml code to extract the article, title and publish date. I would have loved to also extract more features like keywords and the authors but time is always to short. It was this weekend when I finally had the data set after some great help from the RapidMiner staff to figure out the xPath queries.
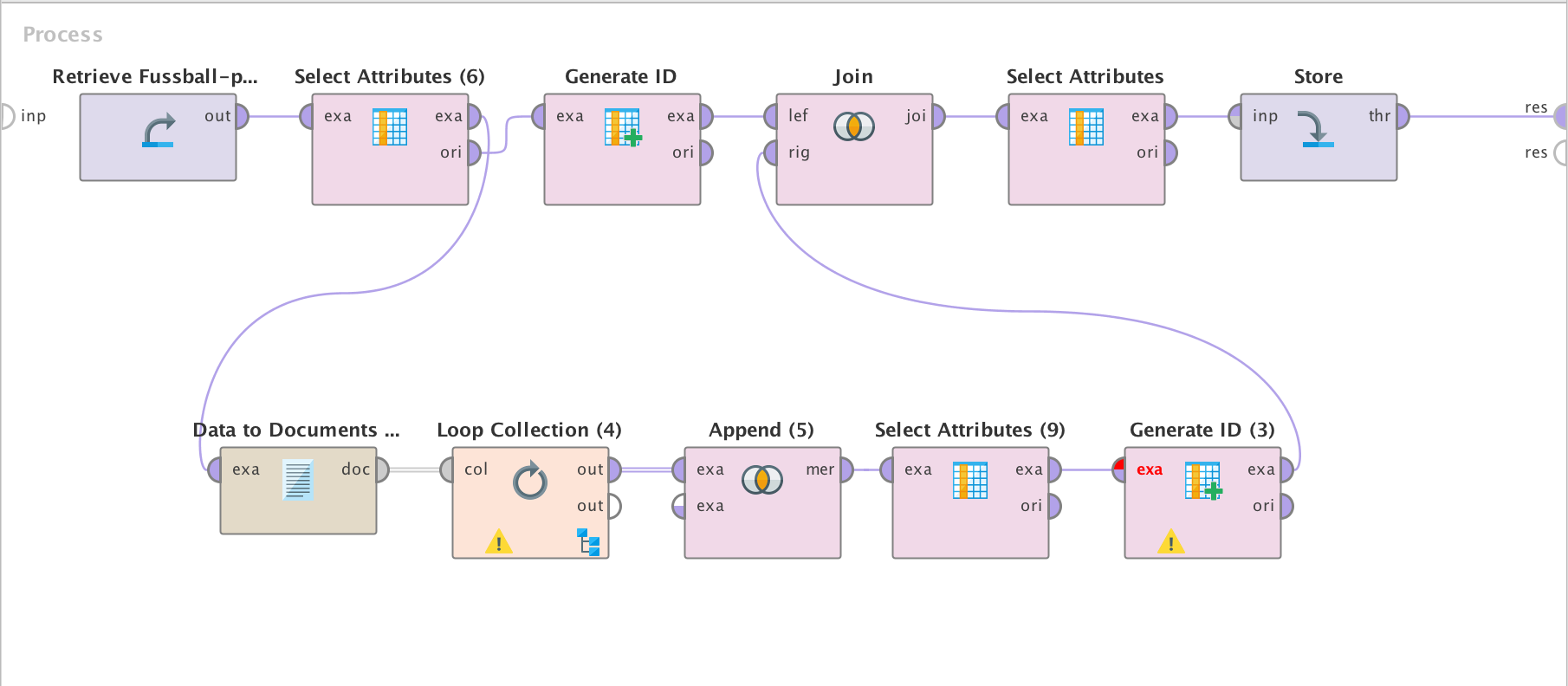
Top level for the data extraction from the very complex XHTML

Digging deeper into the first Loop

Even deeper into the next loop
At this time I was really excited to do some sentiment or even entity sentiment analysis on the given articles. Looking at a small sample I quickly realised that this was not working for me. Rosettes API currently does only support English and Spanish for sentiment analysis and most other functions. Bummer, but they already announced to expand their functions to other languages so there is hope to return to this another time.
So I needed a plan C at this stage and decided on entity extraction to determine who is making the most buzz on SpiegelOnline.de. And I must admit, the results from RapidMiner looked promising when they were collected. The API returned not only the entities but also their entity type, like PERSON or ORGANISATION.

Rosette API’s Extract Entities in RapidMiner
The data extract was then forwarded to Tableau (which I’m still a newbie for) to do some nicer data visualization on the appearance of the 1. Bundeliga clubs. I had to merge a few entities together (i.e. Bayern München and FC Bayern) and probably there is an error in regards to Bayer and Bayer Leverkusen. I also suspect that the entity detection did not detect HSV as an organisation since Hamburger SV is appearing not very often in the articles but Spiegel is writing quite much about that club since it’s located in the same town as their main offices. So here are my results (block size>> count per column; color>> percentage difference to previous column):

So let’s do some quick discussion: The most prominent clubs on SpiegelOnline are the Dortmund, Leverkusen, München and Schalke. These are the common big players and thus it was already expected by me. February and April are month with a lot of buzz for almost all clubs, that’s the time when the DFB championship takes place and the transfer market happens also in January and is pushing into February regarding news.
I would have loved to do more on the data for this project but sometimes you need to cut it down. But the data is still there and maybe some day I’ll have a free weekend and Rosette API has the functions expanded to more languages.
Until then, I’m happy for your comments or questions below! 🙂

A Data Science consultant working at Sopra Steria. He occasionally blogs about data and related topics here and is the host of the Dortmund Data Science Meetup.
Leave a Reply